
前言
最近半年里,我先后完成了PSGameSpider与EverydayNews
这两个项目,它们都是基于GithubPages的静态页,但其中都多多少少可以实现动态站的部分功能,如识别网址后的?xxx=xxx并作出反馈(EverydayNews),或者动态根据Github中的仓库内容渲染页面(PSGameSpider)。
不过,这实质上也并没有改变这作为静态站的本质,因为这不符合动态站“个性化为不同用户展示页面”的特点。
实际上,“伪动态”这个名词是类比“伪静态”而产生的,但不同于伪静态中可以用服务器正则判断并生成网页,静态站中想要实现部分动态站的效果就只能靠在用户的设备上执行脚本,并使用已有的静态资源做出反馈。
下面是其中一部分功能的实现效果及方法:
效果
链接识别
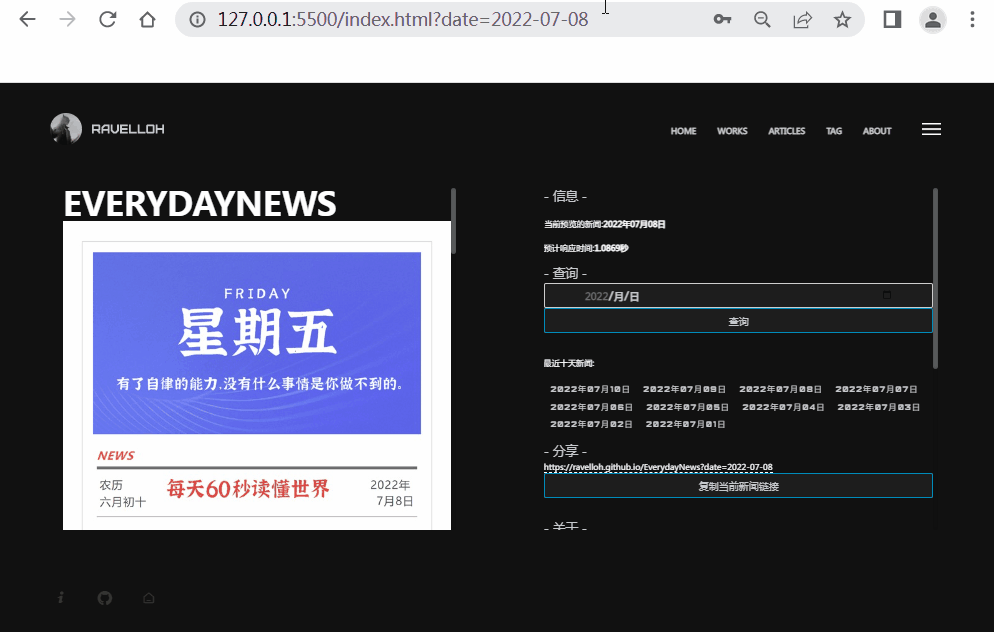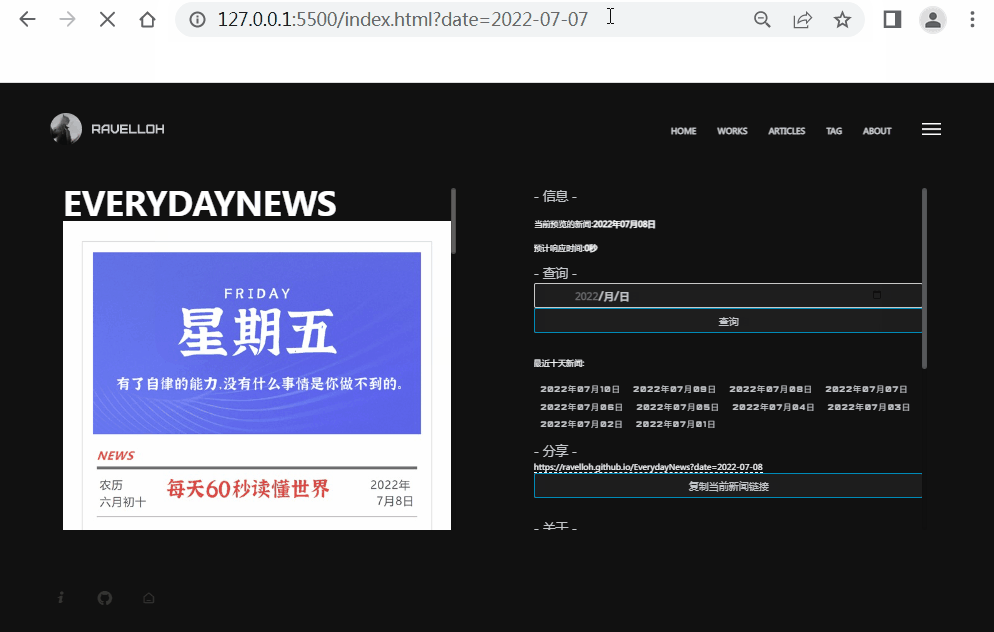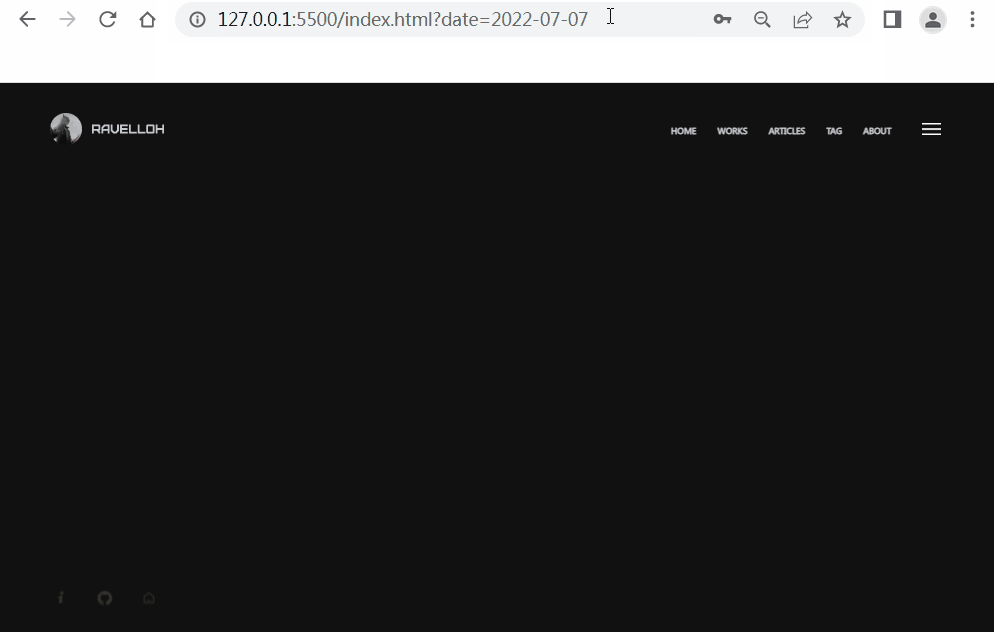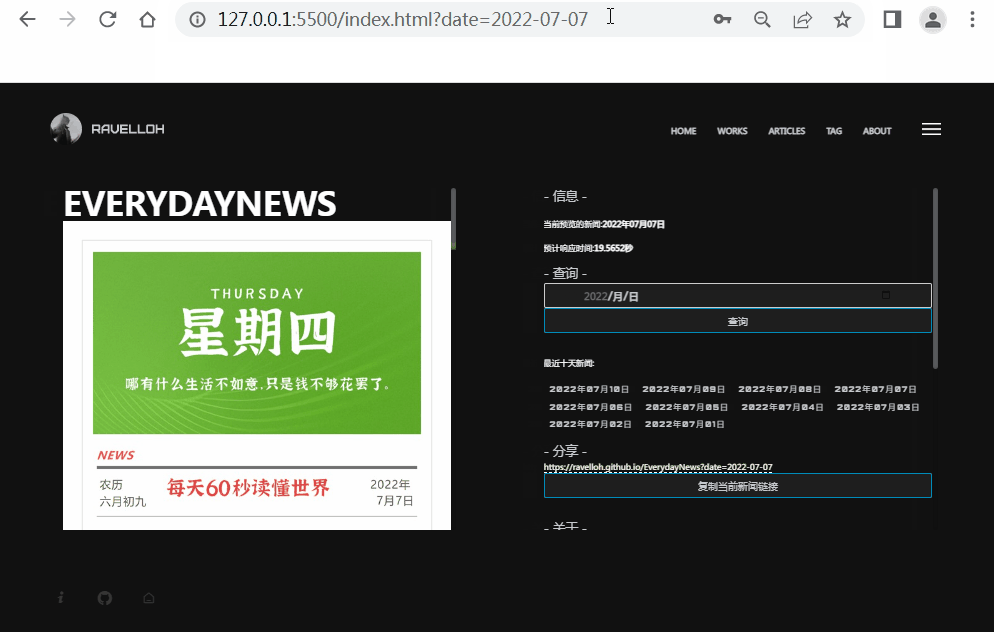
页面自动生成详见Github:PSGameSpider。
实现方法
链接识别
JavaScript中自带有识别当前页面的链接的方法window.location.search,可以用来识别当前页面的链接。
local.search可以识别链接中带?及其后的内容。除此之外,还有下列类似的获取页面url的方法:
*注:下列列表中的内容可以点击执行以查看效果。为了充分展示所有功能,建议先点击此处补充全链接内容。
// JavaScript
var local = window.location.search;
if (local.substring(0, 6) == '?text=') {
var text = local.substring(6);
alert(text);
} else {
alert('没有text参数');
}
>>运行<<
上述代码中实现了一个识别当前页面的链接的方法,如果识别的链接中包含了一个参数,这个参数的名字是text,那么就会弹出一个提示框,提示这个参数的值。
但是此方法也有局限性,就是只能识别一个参数,如果链接中有多个参数,那么就会带着后面的参数一起输出。
为了解决这个问题,我们可以从参数的分割符&下手,当存在&时截断数据:
// JavaScript
var local = window.location.search;
if (local.substring(0, 6) == '?text=') {
var text = local.substring(6);
var text2 = text.substring(0, text.indexOf('&'));
alert(text2);
} else {
alert("没有text参数");
}
>>运行<<
不过这样还不够优雅,如果我们需要的参数没有排在第一位,那么我们可以使用正则表达式来实现:
// JavaScript
var local = window.location.search;
var reg = /text=(.*)/;
var result = reg.exec(local);
if (result != null) {
alert(result[1]);
} else {
alert("没有text参数");
}
>>运行<<
通过对上面的代码的进一步加工,我们就能做到分别提取参数的值,并且可以解决多个参数的问题。
下面是一个完整的例子:
// JavaScript
//判断有没有"?"
var local = window.location.search;
if (local.substring(0, 1) == '?') {
//如果只有一个参数,那么直接弹出提示框
if (local.substring(1).indexOf('&') == -1) {
alert(local.substring(1));
} else {
//遍历替换所有&为?
var local = window.location.search;
var reg = /&/g;
var result = reg.exec(local);
if (result != null) {
local2 = local.replace(reg, "?");
}
//删除相邻的?
var reg2 = /\?{2,}/;
var result2 = reg2.exec(local2);
if (result2 != null) {
var local3 = local2.replace(/\?{2,}/, "?");
} else {
var local3 = local2;
//在最后加入一个?,方便截取
var local4 = local3 + "?";
console.log(local4);
//以?为分割符,循环遍历截取每一个参数并存储在数组中
var reg3 = /\?/;
var result3 = reg3.exec(local4);
var arr = [];
while (result3 != null) {
var local5 = local4.substring(0, local4.indexOf("?"));
arr.push(local5);
local4 = local4.substring(local4.indexOf("?") + 1);
result3 = reg3.exec(local4);
}
//删除arr中的空元素
var reg4 = /^\s*$/;
for (var i = 0; i < arr.length; i++) {
if (reg4.exec(arr[i]) != null) {
arr.splice(i, 1);
i--;
}
}
//遍历arr数组,并输出=前面的值与=后面的值
for (var i = 0; i < arr.length; i++) {
var reg5 = /=/;
var result5 = reg5.exec(arr[i]);
if (result5 != null) {
var local6 = arr[i].substring(0, arr[i].indexOf("="));
var local7 = arr[i].substring(arr[i].indexOf("=") + 1);
alert("参数" + local6 + "的值为" + local7);
}
}
}
} else {
alert("没有参数");
}
>>运行<<
页面自动构建
当然,自动构建代码需要平台支持,这就不可避免的需要用到服务器。
但是在本地无服务器的情况下,也可以上云,比如Github的Actions以及其他类似的服务。
下面以Github Actions为例,演示如何使用Github Actions来自动构建页面:
Github Actions
简而言之,Github Actions就是一个云端的持续集成服务器。想要使用Github,只需要将相应代码传至Github仓库,在其中配置Actions即可。Actions的配置也很简单,只需在仓库内新建
.github/workflows/main.yml文件即可。在此yml文件中,可以设置触发方式(如定时、每次提交、每次修改),以及触发条件(如提交的文件、提交的分支)。
另外要执行的代码内容,依选择的平台的命令行格式来执行即可。比如要执行一Python脚本,可以在yml文件中写:
jobs:
build:
runs-on: ubuntu-latest #设置运行环境
steps:
- name: Checkout
uses: actions/checkout@v2
- name: 'Git set'
run: |
git init
git pull
- name: 'Set up Python'
uses: actions/setup-python@v1
with:
python-version: 3.7 #v3
- name: 'Install requirements'
run: |
pip install wget
pip install bs4
pip install urllib3 #安装依赖
- name: 'Working'
run:
python update.py #运行主程序
使用Github Actions
因为Github Actions是一个云端的持续集成服务器,所以可以在Github上配置Actions,然后在Github上提交代码,就可以自动构建页面。但这并不能达到自动构建页面的目的。想要自动部署,目前有两种方式:
1. Github Actions + 爬虫
这个方法能实现全自动的内容抓取、分析、部署。下面以Python为例,讲讲大致的过程:
首先需要明确要爬取的内容类型,如图片、文字、视频等。针对这些,如果网站需要展示相应的内容,那么就有使用原内容\下载至Github后展示两种思路。
展示原内容的,即爬虫只爬取资源链接(或文字),然后写入页面;
下载至Github,即爬虫爬取链接后下载内容,并使用Git将下载的内容提交至仓库,然后使用GithubPages展示。
下载至Github的爬虫
如只是简单的复制内容,如爬取相应网站的css、js、html等并部署到自身
如果在网站中需要存档资源方便查询,或者是源网站为非静态导致链接更换频繁,那么可以使用第二种方式。
不过两者都有一定的局限性,例如前者不下载资源可能在网站结构改变或者动态站内容更新时,无法自动更新,而后者可能会导致资源冗余等问题。
所以最好的方法是两者结合,并以不同资源类型而分情况使用。
比如下载图像、文件等资源,并将相应文字资源直接写入html,然后配套修改链接即可。
例我的项目为Github:RavelloH/PSGameSpider,其中包含了一个爬虫,用于爬取游戏资源。
此项目的Github Actions配置如下:
# YAML
name: update
on:
schedule:
- cron: '30 5/12 * * *' #每日更新
watch:
types: [started]
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest #运行环境
steps:
- name: Checkout
uses: actions/checkout@v2
- name: 'Git set'
run: |
git init
git pull
- name: 'Set up Python'
uses: actions/setup-python@v1
with:
python-version: 3.7 #v3
- name: 'Install requirements'
run: |
pip install wget
pip install bs4
pip install urllib3 #安装依赖
- name: 'Working'
run:
python update.py #运行主程序
- name: 'Page'
run:
python webpage.py #运行主程序
- name: 'EnglishWorking'
run:
python en-update.py #运行主程序
- name: 'EnPage'
run:
python en-webpage.py #运行主程序
- name: TOC
uses: technote-space/toc-generator@v4
- name: Record time
run: echo `date` > date.log
- name: Commit files
run: |
git diff
git config --local user.email "hyh20060327@qq.com"
git config --local user.name "RavelloH"
git add -A
git commit -m "`date '+%Y-%m-%d %H:%M:%S'`" || exit #动态提交信息
git status
git push -f
env:
GITHUB_TOKEN: $\{\{ secrets.GITHUB_TOKEN \}\}
另外,也可以使用另一种方法:
爬虫爬取到资源后,前端通过JavaScript将固定命名的资源文件引入,这样也能实现资源的动态更新。
不过这对资源形式的要求较高,要求每天只能有固定数(或者换句话说,资源的数目是可预判的)的资源类型。
使用这种方法的项目详见EverydayNews
前端JS代码实现
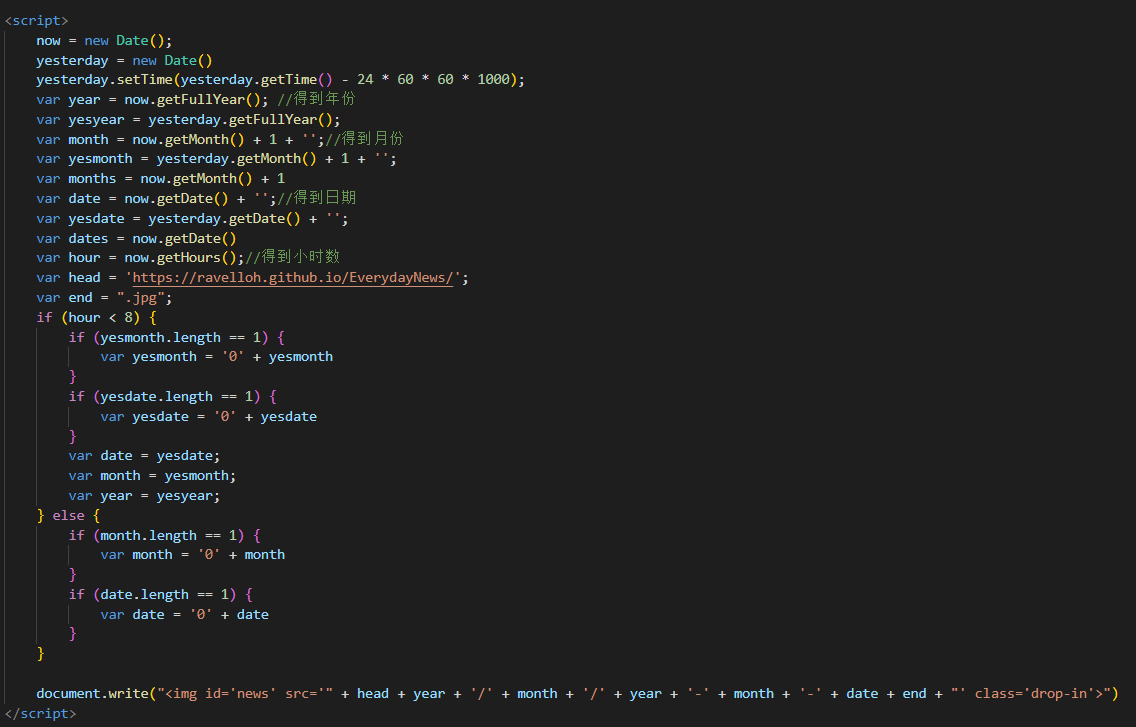
API + 前端即时渲染
这部分没什么好说的,看具体API返回的格式就行。返回text的就直接
document.write()*外联拖慢加载速度或者.innerHTML()写入即可;返回json的就需要使用
JSON.parse()解析,然后再写入即可。(当然要是格式稳定,也可以切分字符串)返回图片的也可以直接img引入即可,但是要注意图片的格式,要是png的话,要加上
data:image/png;base64,。这部分最难的是找API,使用起来也很方便,看具体文档就行。